Model selection for LR via AR
Changpetch P, Lin DK. Model selection for logistic regression via association rules analysis. Journal of Statistical Computation and Simulation. 2013 Aug 1;83(8):1415-28.
一句话介绍,为了逻辑回归有更好的结果,使用关联规则产生新的特征以生成一个最优模型。
Motivation
某些变量间存在相互作用(interaction),需要将变量和变量之间的相互作用同时加入LR模型。
使用关联规则来探索变量间的相互作用。
算法
-
产生关联规则
CBA算法,mini_support = 0.1,mini_confidence = 0.8
rule example: $X_1=0 \& X_2=1\rightarrow Y=0$
-
规则筛选
选择30~50个置信度最高的规则。
-
产生特征
将关联规则后项去除,即为新的特征。
feature example: $X_1(0)X_2(1)$
-
模型搜索
根据上面产生的特征生成最终的模型,使用AIC(Akaike information criterion; Akaike 1974)作为模型选择的损失函数进行搜索。
或者使用lasso(least absolute shrinkage and selection operator; Tibshirani 1996)、SCAD(smoothly clipped absolute deviation; Fan 1997)、BIC(Bayesian information criterion; Schwarz 1978)等方法。
实验
论文所使用的数据集是CMU于1991年提出的MONK数据集,二分类问题,每个样本具有6个离散值的属性,数据集共包含432个样本,即包含所有可能出现的组合情况($3\times3\times2\times3\times4\times2=432$)。
| attribute | values |
|---|---|
| head_shape | {round, square, octagon} |
| body_shape | {round, square, octagon} |
| is_smiling | {yes, no} |
| holding | {sword, balloon, flag} |
| jacket_color | {red, yellow, green, blue} |
| has_tie | {yes, no} |
MONK数据集由独立的三个数据集构成,每个数据集的标签分类规则不同。论文仅使用第一个数据集monks-1,此数据集标签按照如下标准划分:
For a sample, if head_shape = body_shape or jacket_color = red, it’s in Class 1; otherwise it’s in Class 0.
测试集即为有标签的全部432个样本,训练集为从中随机选取的124个样本,无噪声。
这篇论文对离散变量的编码方式有点奇怪。
以上数据集为例,其使用11个二值变量编码6个原始变量。
若目的是将多值离散变量进行二值化,直接使用 One-Hot 编码也仅需要17个编码位,为什么不直接使用One-Hot?
| attribute | variables {values} |
|---|---|
| head_shape | $X_1,X_2$ {1*, 01, 00} |
| body_shape | $X_3,X_4$ {1*, 01, 00} |
| is_smiling | $X_5$ {1, 0} |
| holding | $X_6,X_7$ {1*, 01 , 00} |
| jacket_color | $X_8,X_9,X_{10}$ {1**, 01*, 001, 000} |
| has_tie | $X_{11}$ {1, 0} |
实验结果
模型
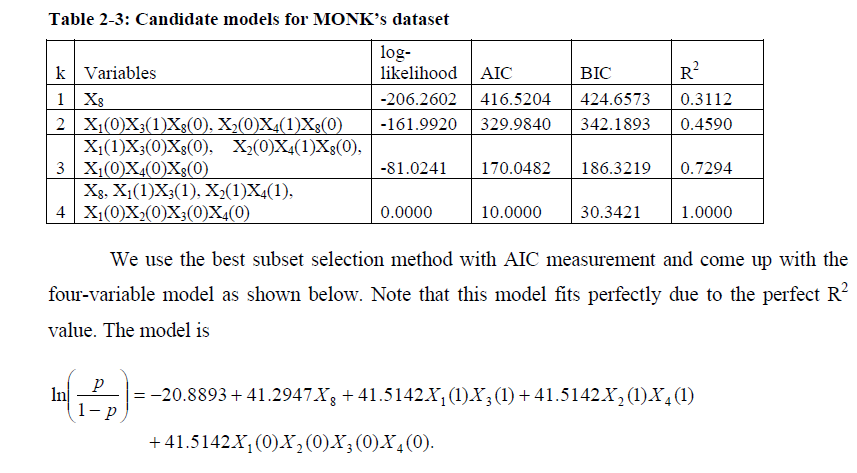
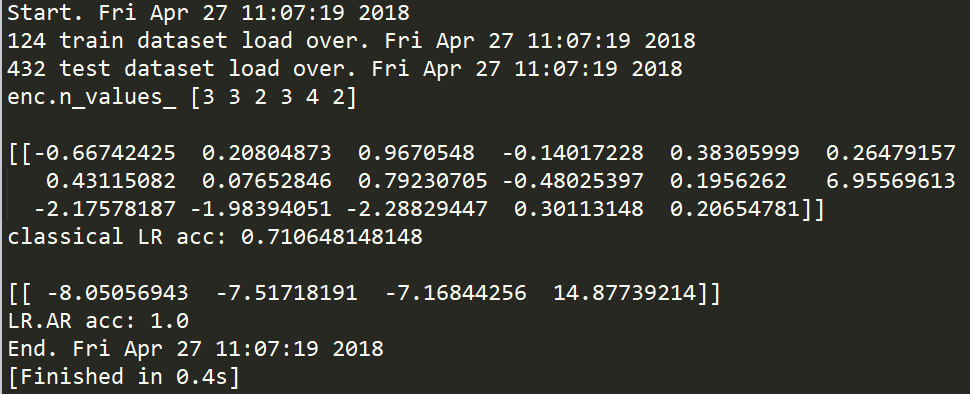
复现结果
# LR.AR model 4
line = np.array([e[0]^e[3], e[1]^e[4], e[2]^e[5], e[11]])
Reference
[1] UCI上MONK数据集主页