SENet Note
SENet 是 ImageNet 2017 的冠军模型,全称为 Squeeze-and-Excitation Networks。
arXiv链接:https://arxiv.org/abs/1709.01507
SENet 机制一句话介绍就是 reweight channel,即为每个通道加上一个自适应权重系数。
1 权重系数怎么计算?
1.1 SEBlock架构
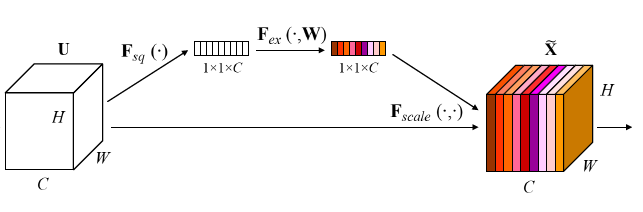
- Squeeze,将每个channel二维的 feature map 转换为一维数值输出 $ {U_1, U_2,\cdots,U_c}\rightarrow {k_1, k_2,\cdots,k_c}$;
- Excitation:对通道的输出值进行combine,最后进行sigmoid归一化 $ {k_1, k_2,\cdots,k_c} \rightarrow {k’_1, k’_2,\cdots,k’_c}$;
- 最后将 ${k’_1, k’_2,\cdots,k’_c}$ 作为权重系数,对每个channel 的 feature map 进行自适应 scale。
1.2 模块实现
- Squeeze 通过 avgpool实现;
- Excitation 通过两个全连接层来实现。
2 实现细节
2.1 压缩率
由于SEBlock中使用了两个全连接层来作为 Excitation 结构提取 channel 间的相关性。
所以为了减少计算量,第一层全连接的channel数量设为一个较少的值,以超参描述为输入channel数量的 $\cfrac{1}{r}$。
作者的实验表明当 $r=16$ 时,能够在仅损失微弱精度的情况下大幅降低模型计算量。
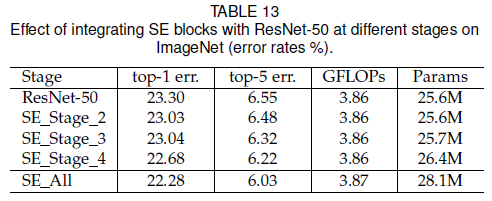
2.2 加多少个?
作者在ResNet的实验表明,在越靠后的 stage 上添加 SEBlock 对模型的提升越明显。
并且,在所有 stage 上都添加 SEBlock 的结果是最好的。
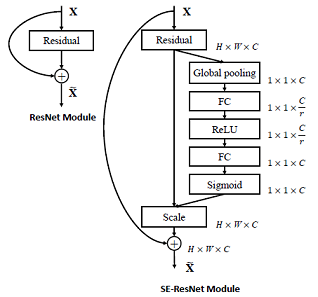
2.3 加在残差前后?
作者的实验表明,SEBlock 只要加在残差模块之内区别都不大;若加在残差模块之外则效果比较差。
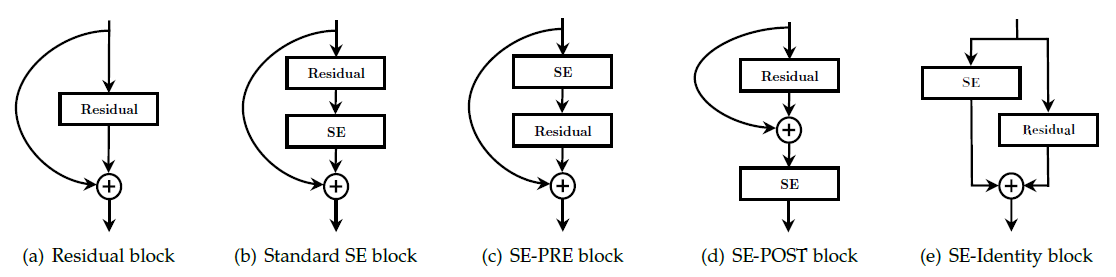
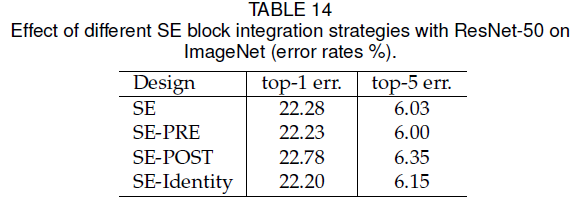
并且,如果 SEBlock 直接加在 $3\times3$ 卷积层后,参数量会明显减少,因为 ResNet Bottleneck中 $3\times3$ 卷积前对channel 数量进行了压缩。
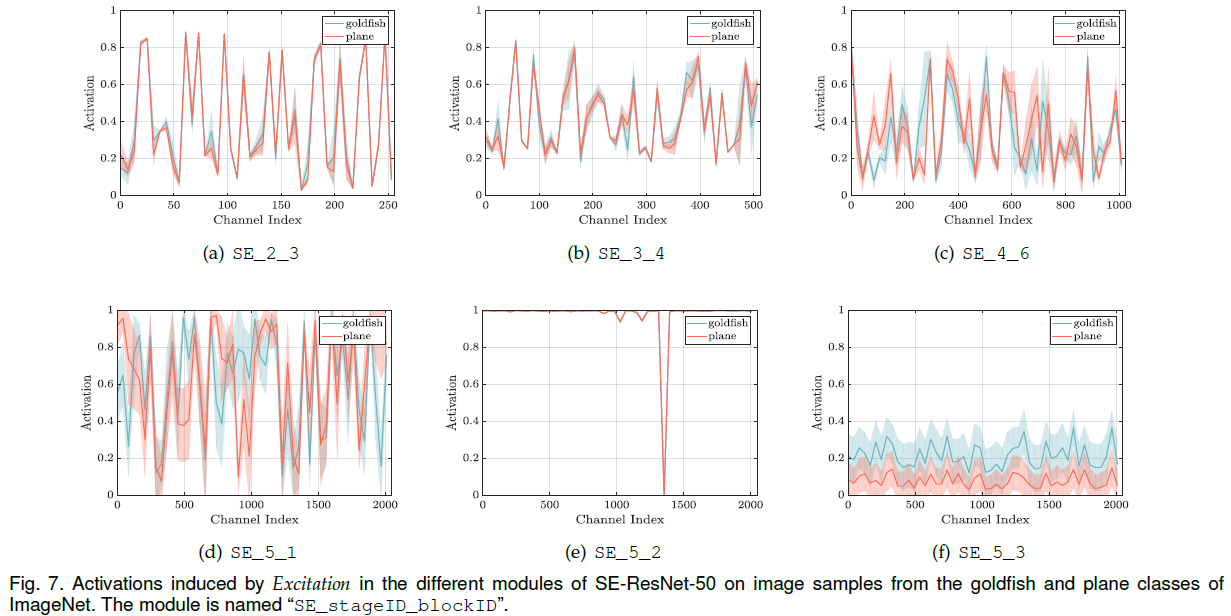
3 权重系数分布
作者可视化了对于不同类的输入,整个网络层的 Excitation 权重系数分布。
越靠后的SEBlock,其权重系数越有区分度,这与在不同stage添加SEBlock对模型的提升结果相吻合。
唯一的例外是最后一层的SEBlock,其结果近似于恒等映射,加不加没啥区别。